If you’d rather skip straight to the verdict, feel free to jump to conclusions.
Intro
You send PostgreSQL an INSERT. It replies INSERT 0 1. The row is there.
That’s usually enough. But at some point I found myself wondering: what actually happened? Not at the SQL level, but underneath. Where did the bytes go? In what order? What guarantees that a crash between the INSERT and the COMMIT doesn’t leave the table in a broken state?
I went looking for a single document that traced the full path and didn’t find one. The official docs are thorough but organized by feature, not by journey. The Internals of PostgreSQL by Hironobu Suzuki is the best deep-dive I found, and much of what’s here draws from it.
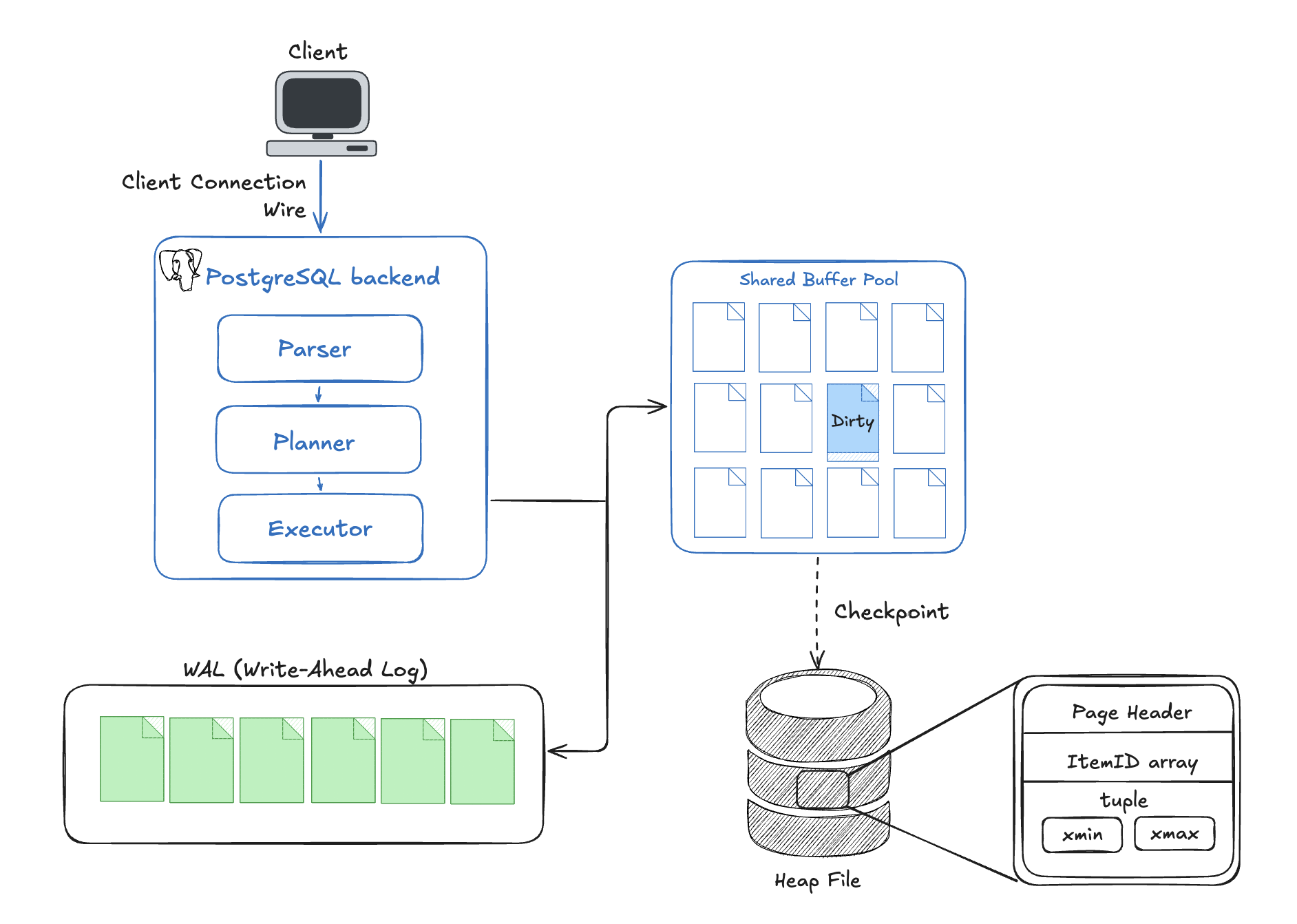
This post is my attempt to trace one INSERT from arrival to disk, touching each system along the way:
- The parser and planner, which turn SQL text into an execution plan
- The executor, which forms the actual tuple and acquires locks
- The shared buffer pool, PostgreSQL’s in-memory page cache
- The Write-Ahead Log (WAL), which is the foundation of crash safety
- The heap file, where rows ultimately live on disk
- MVCC, which controls which transactions can see which rows
- The checkpointer, which reconciles the WAL with the heap files
Some of this I understood before writing it. Some of it I didn’t until I had to explain it.
The Query Arrives
PostgreSQL actually documents the path of a query in its internals section. I hadn’t read it before writing this. It’s a good starting point.
Connection
Before any SQL is parsed, a connection has to be established. PostgreSQL uses a process-per-connection/user model: a postmaster process listens for incoming connections (at a specified TCP/IP port). When one arrives, postmaster calls fork(), a Unix system call that creates a copy of the calling process. The child inherits the parent’s memory and file descriptors, then goes off independently to handle your connection. That copy is the backend process. It lives for the duration of the connection and exits when it closes.
fork()exists because in Unix, you can’t conjure a process from nothing. The only way to create one is to copy an existing one. PostgreSQL leans into this:postmasteralready has shared memory set up and config loaded, so forking it gives the child everything it needs without rebuilding from scratch.
This means every client connection is an OS process. It works well up to a few hundred connections, but at scale it becomes expensive. That’s why connection poolers exist: they sit between your application and PostgreSQL, multiplexing many application connections onto a smaller number of backend processes. PgBouncer is the most widely used. pgcat is a newer Rust-based alternative that also supports sharding. Supabase built their own called Supavisor for multi-tenant cloud use. If you’re on AWS RDS, there’s no pooler by default. RDS Proxy is Amazon’s managed option, which sits in front of your RDS instance and does the same job.
For our purposes, assume the connection is already open. The INSERT string arrives at the backend process and the real work begins.
Parsing
The backend passes the raw SQL string to the parser, which does two things. First, a lexer breaks the string into tokens. Then a grammar (derived from the bison grammar file in the source, which is famously large) builds a parse tree from those tokens.
This is the same process a compiler or interpreter uses. Go, Python, and JavaScript all lex and parse source code the same way, producing an Abstract Syntax Tree (AST). PostgreSQL’s parse tree is the same idea, just for SQL. The grammar is even written in bison, the same tool used by many language compilers.
The difference comes after. A compiler type-checks the AST and generates machine code. PostgreSQL checks whether the referenced tables and columns actually exist, builds an execution plan, and runs it against its storage engine.
The parse tree itself doesn’t know any of that yet. It only knows the syntactic shape of the query: that there’s an INSERT, a target table name, a column list, and a values list. Whether the table exists or the types match is someone else’s problem.
Query Rewrite
After parsing, the query passes through the rule system. PostgreSQL has a general-purpose rewrite mechanism that can transform one query into another, and views are implemented on top of it. When you query a view, the rewriter replaces the view reference with the underlying query.
For a plain INSERT into a real table with no rules attached, this stage is essentially a pass-through. But it’s part of the pipeline, and knowing it exists matters if you’re ever confused about why a query against a view behaves differently than you expect.
Planning
After the rewriter, the query goes to the planner. The planner’s job is to figure out the most efficient way to execute the query. For a SELECT with joins, subqueries, and indexes, this is genuinely hard. The planner considers many possible execution strategies and picks the one with the lowest estimated cost.
For a plain INSERT, there’s almost nothing to plan. There’s no join to reorder, no index to choose for scanning, no alternative path. The data goes into the table. The planner still runs, it just doesn’t have much to decide.
What it does produce is a plan tree, a structure that the executor will walk to carry out the query. You can see what this looks like with EXPLAIN:
EXPLAIN INSERT INTO users (name, email) VALUES ('ada', 'ada@example.com');Insert on users (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)Two nodes. Result produces the row from the literal values. Insert writes it to the table. Compare that to a SELECT with a join and you’d see a much deeper tree with many more decisions baked in.
The planner is worth knowing about even when it’s idle, because the moment your INSERT has a SELECT subquery, a RETURNING clause feeding into something larger, or triggers that fire additional queries, the planner starts doing real work.
Executor
The executor walks the plan tree produced by the planner and carries out the actual work. For our INSERT, that means taking the literal values from the Result node and writing them to the table via the Insert node.
Before writing anything, the executor acquires a RowExclusiveLock on the table. This is a lightweight lock that allows concurrent reads and other inserts, but blocks operations that would conflict, like ALTER TABLE or TRUNCATE. PostgreSQL’s locking documentation lists the full lock hierarchy, but for a normal INSERT this lock is rarely the source of contention.
Tuple formation
I don’t know if it is surprising or not, but a row in PostgreSQL is not just your data. It’s a tuple with a header that contains metadata PostgreSQL uses to manage concurrency and visibility. The system columns are:
xmin- the transaction ID that created this tuplexmax- the transaction ID that deleted or updated this tuple (0 if neither has happened)ctid- the physical location of the tuple: which page it’s on and where within that page
You can query these directly:
INSERT INTO users (name) VALUES ('ada');
SELECT xmin, xmax, ctid, name FROM users WHERE name = 'ada'; xmin | xmax | ctid | name
------+------+-------+------
742 | 0 | (0,1) | adaxmin is 742, the ID of the transaction that inserted this row. xmax is 0, meaning no one has deleted or updated it. ctid is (0,1), meaning it’s the first tuple on page 0 of the heap file.
These fields are the foundation of MVCC (multi-version concurrency control). When another transaction reads this row, PostgreSQL checks xmin against a snapshot of which transactions were committed at the time that reader started. If the inserting transaction hadn’t committed yet when the snapshot was taken, the row is invisible to that reader. The data is there on disk, it’s just hidden behind a transaction ID check.
The executor sets xmin to the current transaction ID when it forms the tuple. That single field is what keeps an in-progress insert invisible to everyone else until commit.
The Buffer Pool
After the executor forms the tuple, it doesn’t write directly to disk. It writes to the buffer pool, PostgreSQL’s in-memory page cache, controlled by the shared_buffers setting.
The buffer pool is a fixed pool of 8KB pages shared across all backend processes. When the executor needs to insert a tuple, the buffer manager finds the right page for that table (loading it from disk first if it isn’t already in memory), writes the tuple into it, and marks the page as dirty, meaning it has been modified in memory but not yet written back to disk.
At this point, your row exists only in shared memory. Nothing has touched the disk.
That might sound alarming. If the server crashes now, is the data lost? This is exactly the problem WAL solves, and we’ll get to it in the next section. The short answer: a WAL record is written before the insert is considered committed, so a crash doesn’t lose data even if the dirty page never made it to disk.
Seeing the buffer pool
The pg_buffercache extension lets you inspect the buffer pool directly:
CREATE EXTENSION pg_buffercache;
SELECT
c.relname,
count(*) AS buffers,
count(*) FILTER (WHERE b.isdirty) AS dirty
FROM pg_buffercache b
JOIN pg_class c ON c.relfilenode = b.relfilenode
WHERE c.relname = 'users'
GROUP BY c.relname; relname | buffers | dirty
---------+---------+-------
users | 3 | 1One dirty buffer means one page with unflushed changes. After a checkpoint flushes it to disk, the dirty count drops to zero.
How full buffers are handled
The buffer pool is fixed in size. When it fills up and a new page needs to be loaded, PostgreSQL evicts something. It uses a clock-sweep algorithm (and also here) rather than strict LRU. Each page has a usage count that increments on access and decrements on clock sweeps. Pages with a count of zero are eviction candidates. Dirty pages are written to disk before being evicted.
The default shared_buffers is 128MB, which is conservative. For a dedicated database server, 25% of RAM is a common starting point.
WAL (Write-Ahead Log)
Before the dirty buffer page ever reaches disk, PostgreSQL writes a record of the change to the Write-Ahead Log. The rule is simple: the log record must be flushed to disk before the change is considered committed. If the server crashes, PostgreSQL replays the WAL on startup to recover any changes that didn’t make it into the heap files.
This is the answer to the question from the previous section. Your row is safe in shared memory because a durable record of it already exists in the WAL.
Each WAL record is stamped with a Log Sequence Number (LSN), a monotonically increasing position in the log. You can see the current LSN:
SELECT pg_current_wal_lsn();WAL is not a PostgreSQL invention. It’s a pattern used by almost every serious storage system: CockroachDB, RocksDB, SQLite, etcd. The core idea is the same everywhere. I’m planning a separate post that goes deeper into how write-ahead logging works across these systems.
The Heap File
Eventually, the dirty buffer page gets flushed to disk. What it lands in is called the heap file. The name “heap” here doesn’t mean the memory heap. It means the data is stored in no particular order, as opposed to an index which maintains a sorted structure. Every table has one or more heap files on disk.
The physical layout is described in detail in the PostgreSQL docs, and the diagram at the top of this post shows it visually. Here’s how it breaks down.
Pages
Heap files are divided into pages of exactly 8KB. Every read and write to disk happens at the page level. Even if you insert a single row, PostgreSQL loads the entire 8KB page into the buffer pool, modifies it, and eventually writes the whole page back.
Each page has three parts:
- A page header containing metadata: the LSN of the last WAL record that modified this page, the amount of free space, and some flags.
- An ItemId array that grows from the front of the page. Each entry is a small pointer (offset + length) to a tuple somewhere in the page.
- Tuple data that grows from the back of the page toward the ItemId array. Free space sits in the middle.
When a new row is inserted, PostgreSQL appends a tuple at the back of the page and adds a new ItemId entry at the front pointing to it.
Tuples
Each tuple has a header followed by the column data. The header contains the xmin, xmax, and other fields we saw earlier when querying system columns. The ctid value (0,1) from that query means: page 0, ItemId slot 1. Follow that ItemId pointer and you find the tuple.
One thing the header also contains is a null bitmap, one bit per column, indicating which columns are NULL. NULL values take no space in the tuple data itself.
Large values and TOAST
8KB pages create a problem for large values. A single text column with a multi-megabyte string won’t fit. PostgreSQL handles this with TOAST (The Oversized-Attribute Storage Technique). Values larger than roughly 2KB are compressed and/or moved to a separate TOAST table. The main tuple stores a pointer to the out-of-line value instead. This happens automatically and is invisible at the SQL level.
MVCC and Transaction Visibility
We’ve seen that when the executor inserts a tuple, it sets xmin to the current transaction ID. That field is what makes the row invisible to other transactions until the insert commits. This is the core of MVCC, multi-version concurrency control.
The idea is that instead of locking a row so only one transaction can touch it at a time, the database keeps multiple versions of the row and uses transaction metadata to decide which version each reader should see. Readers don’t block writers. Writers don’t block readers. Each transaction gets a consistent snapshot of the data as it existed when that transaction started.
For the INSERT, the mechanics are straightforward: the new tuple has xmin set to our transaction ID and xmax set to 0. Any other transaction that reads the table takes a snapshot of which transaction IDs were committed at that moment. If our transaction hasn’t committed yet, its ID isn’t in that snapshot, so the tuple is invisible. Once we commit, subsequent snapshots include our ID and the row becomes visible.
The interesting complexity is in updates and deletes. An UPDATE in PostgreSQL doesn’t modify the existing tuple. It writes a new version of the tuple with the new values, sets xmax on the old tuple to mark it as superseded, and links them together. This is why VACUUM exists: old tuple versions accumulate and need to be cleaned up.
MVCC is not a PostgreSQL invention either. CockroachDB, MySQL InnoDB, and Oracle all implement it, each with different tradeoffs. I’m planning a separate post on how it works across these systems.
Checkpointing
The WAL keeps growing. Dirty buffer pages keep accumulating. At some point PostgreSQL needs to reconcile the two: flush dirty pages to the heap files on disk and record a point in the WAL up to which everything is safely written. That process is a checkpoint.
During a checkpoint, the checkpointer process writes all dirty pages from the buffer pool to their corresponding heap files, then writes a checkpoint record to the WAL marking the position. On crash recovery, PostgreSQL only needs to replay WAL records from the most recent checkpoint forward. Everything before it is already in the heap files.
Checkpoints happen automatically on a schedule controlled by checkpoint_timeout (default 5 minutes) or when the WAL grows past max_wal_size (default 1GB). You can also trigger one manually:
CHECKPOINT;Checkpoints are intentionally spread out over time rather than flushing everything at once. The checkpoint_completion_target setting (default 0.9) tells PostgreSQL to finish writing dirty pages within 90% of the interval between checkpoints. This smooths out the I/O spike that would otherwise happen if hundreds of dirty pages all hit disk simultaneously.
One thing that clicked for me reading about this: the heap file on disk is not always up to date. Between checkpoints it can be behind what’s in memory and in the WAL. That’s fine, because the WAL is the source of truth. The heap files are just a materialized view of it.
A Word on RDS Configuration
While PostgreSQL deployed on your own servers is configured by editing postgresql.conf directly, Amazon RDS doesn’t give you shell access to the instance. Instead, configuration is managed through Parameter Groups, a named collection of settings you create in the AWS console (or via CLI or Terraform) and attach to your RDS instance. Some changes apply immediately, others require a reboot.
Most of the parameters discussed in this post have corresponding knobs in RDS. A few worth knowing:
| Parameter | Default | Notes |
|---|---|---|
shared_buffers | ~25% of RAM | AWS sets and scales this with instance size. You can override it, but they don’t recommend it. |
max_connections | 100 | Raise it if you’re hitting connection limits, or front it with RDS Proxy instead. |
checkpoint_timeout | 5 min | Leave it unless you have specific I/O concerns. |
max_wal_size | 1GB | Raise it if you see frequent checkpoints under heavy write load. |
log_min_duration_statement | -1 (off) | Set to e.g. 1000 to log any query that takes over 1 second. The most commonly touched parameter in practice. |
For most teams on RDS, the day-to-day configuration work is limited: log_min_duration_statement for slow query visibility, and max_connections when connection limits become a problem. The rest PostgreSQL and AWS handle well with their defaults.
Conclusion
So, what actually happens when you write a row to PostgreSQL?
Your INSERT string arrives at a backend process forked specifically for your connection. A lexer and parser turn it into a parse tree. The planner produces an execution plan, trivial for a plain insert. The executor forms a tuple with your data and MVCC metadata, acquires a lock on the table, and writes the tuple to a dirty page in the shared buffer pool. Before that write is considered committed, a WAL record is flushed to disk, which is the actual durability guarantee. Eventually, a checkpoint flushes the dirty page to the heap file on disk, and the WAL record is no longer needed for recovery.
The row that appears with INSERT 0 1 passed through all of that.
What I found most useful in tracing this path was seeing how each system exists to solve a specific problem. The buffer pool avoids writing every change directly to disk. WAL makes that safe by logging changes first. MVCC lets readers and writers proceed concurrently by versioning tuples rather than locking them. Checkpointing bounds how much WAL needs to be replayed on startup. Each piece earns its complexity.
WAL and MVCC both deserve more space than one section can give them. I’m planning follow-up posts on each that go deeper and look at how other databases implement the same ideas.
Further Reading
- The Internals of PostgreSQL by Hironobu Suzuki - free, comprehensive deep-dive on everything covered here. Chapters 1 (heap), 5 (WAL), and 9 (checkpoints) are the most relevant.
- Postgres Atomicity by Brandur Leach - focuses on how PostgreSQL guarantees atomicity through WAL and MVCC, with excellent diagrams.
- PostgreSQL internals documentation - the official reference for storage, WAL, and the query pipeline.
Comments