I wrote about MVCC in Postgres, MySQL (InnoDB), and CockroachDB, and now I want to understand how it works in WiredTiger, the storage engine behind MongoDB.
MVCC Recap
MVCC, or Multi-Version Concurrency Control, keeps multiple versions of a row, gives each transaction a snapshot, lets readers and writers proceed without blocking each other.
xmin/xmax (Postgres)
Postgres uses xmin/xmax fields to keep track of the visibility of rows. Each row has an xmin and xmax field, which are set to the transaction id of the transaction that created the row and the transaction id of the transaction that deleted the row, respectively.
CockroachDB - timestamps + HLC
CockroachDB uses hybrid logical clocks (HLC) to keep track of the visibility of rows. Each row has a start and end timestamp, which are set to the HLC of the transaction that created the row and the HLC of the transaction that deleted the row, respectively.
InnoDB (MySQL)
InnoDB uses undo logs to keep track of the visibility of rows. Each transaction is assigned a transaction id. Each row is either the latest version of a row, or an older version that is stored in the undo log. If the row is the latest version, it has a start transaction id and an end transaction id of null. If the row is an older version, it has a start transaction id and an end transaction id that are set to the transaction id of the transaction that created the row and the transaction id of the transaction that deleted the row, respectively.
MongoDB - WiredTiger, why MVCC came late, what it enables
MongoDB delegates storage to WiredTiger, a pluggable storage engine it acquired in 2014 and made the default in MongoDB 3.2. WiredTiger brings its own MVCC implementation, its own concurrency model, and its own cleanup story. MongoDB’s transaction and isolation semantics sit on top of it.
WiredTiger is a key-value store backed by B-trees. MongoDB maps each collection to a WiredTiger B-tree, where the key is the document’s _id and the value is the BSON-encoded document.
Every value in WiredTiger is stored with a timestamp. When a document is updated, WiredTiger writes the new version at the transaction’s commit timestamp and retains the old version at its original timestamp. Readers see the version that existed at their read timestamp. This is structurally similar to CockroachDB’s approach - versions keyed by (key, timestamp) rather than (key, transaction ID) for the same reason - timestamps compose more naturally than integer IDs when multiple components need to agree on ordering.
Snapshots and Read Timestamps
When a read operation starts in MongoDB, WiredTiger assigns it a read timestamp. The read sees all committed versions at or before that timestamp and ignores everything newer.
For single-document operations, this happens implicitly. For multi-document transactions, you control it explicitly through read concern:
| Read Concern | Meaning |
|---|---|
local | Most recent committed data on this node, no timestamp coordination |
majority | Data acknowledged by a majority of replica set members |
snapshot | Consistent snapshot across all documents in the transaction, at the same timestamp |
snapshot read concern is what gives MongoDB consistent point-in-time reads across all documents in a multi-document transaction. Without it, a transaction reading multiple documents could see them at different points in time. Note that this is snapshot isolation, not serializability - write skew anomalies are still possible.
sequenceDiagram
participant T1 as Txn 1 (Writer)
participant WiredTiger
participant T2 as Txn 2 (Reader, snapshot)
T2->>WiredTiger: BEGIN (snapshot at ts=100)
T1->>WiredTiger: UPDATE { balance: 500 } at ts=105
T1->>WiredTiger: COMMIT
T2->>WiredTiger: find({ _id: "acct1" })
Note over WiredTiger: T2 reads ts=100 - returns old version { balance: 400 }
T2->>WiredTiger: COMMIT
T2 sees the document as it existed at ts=100, even though T1 committed a newer version at ts=105. Same guarantee as PostgreSQL’s repeatable read, achieved through timestamps rather than transaction ID snapshots.
Write Conflicts
Unlike PostgreSQL, which detects write-write conflicts when a second transaction attempts to modify an already-locked row (blocking until the first commits or aborts), WiredTiger detects them eagerly. If two transactions attempt to modify the same document, the second one to try gets a WriteConflict error immediately. It does not wait.
MongoDB retries WriteConflict errors automatically for implicit (single-operation) transactions. For explicit multi-statement transactions, the error is returned to the application, which must retry the entire transaction.
This is worth knowing for schema design. Documents that aggregate high-contention data (counters, running totals, queues implemented as arrays, etc) can produce high write conflict rates under concurrent load. The usual fix is either sharding the counter across multiple documents and summing them at read time, or using the $inc operator on isolated fields where atomic increment semantics are sufficient.
Multi-Document Transactions
MongoDB added multi-document ACID transactions in version 4.0 (2018), and extended them to sharded clusters in 4.2. Before that, atomicity was only guaranteed for single-document operations. This shaped MongoDB’s data modeling conventions. Because you couldn’t rely on cross-document transactions, MongoDB’s documentation for years recommended embedding related data in a single document rather than normalizing it across multiple collections. A transaction that would require joining three tables in Postgres could be a single document read in MongoDB.
That recommendation is still often valid, but the reasoning behind it matters. Embedding is not just about performance, it was originally about atomicity. Now that multi-document transactions exist, embedding vs. referencing is a genuine trade-off rather than a safety constraint.
| Feature | Embedding (Denormalization) | Referencing (Normalization) |
|---|---|---|
| Read Performance | Fast: Single disk I/O, no joins needed. | Slower: Requires $lookup or multiple queries. |
| Atomicity | Native: Single-document updates are always atomic. | Transactional: Requires explicit multi-doc transactions. |
| Data Integrity | Risk: Data duplication can lead to inconsistencies. | Clean: Single source of truth for every entity. |
| Growth Potential | Limited: Risk of hitting the 16MB BSON limit. | Unlimited: Relationships can scale indefinitely. |
| Best For | One-to-few, “part-of” relationships. | One-to-many, many-to-many, or shared entities. |
The Oplog and MVCC
Every write in MongoDB (insert, update, delete) is recorded in the oplog, a capped collection in the local database. The oplog is how replica set members replicate writes from the primary to secondaries.
WiredTiger’s MVCC and the oplog interact in a specific way: a write is not visible to other operations until it is both committed in WiredTiger and written to the oplog. This ensures that replication and visibility are consistent - a secondary will never be asked to apply an operation the primary hasn’t fully committed.
This is also why MongoDB’s write concern matters for MVCC semantics:
| Write Concern | Meaning |
|---|---|
{ w: 1 } | Acknowledged once the primary commits |
{ w: "majority" } | Acknowledged once a majority of replica set members have applied it |
A reader using majority read concern will only see writes that have crossed that threshold.
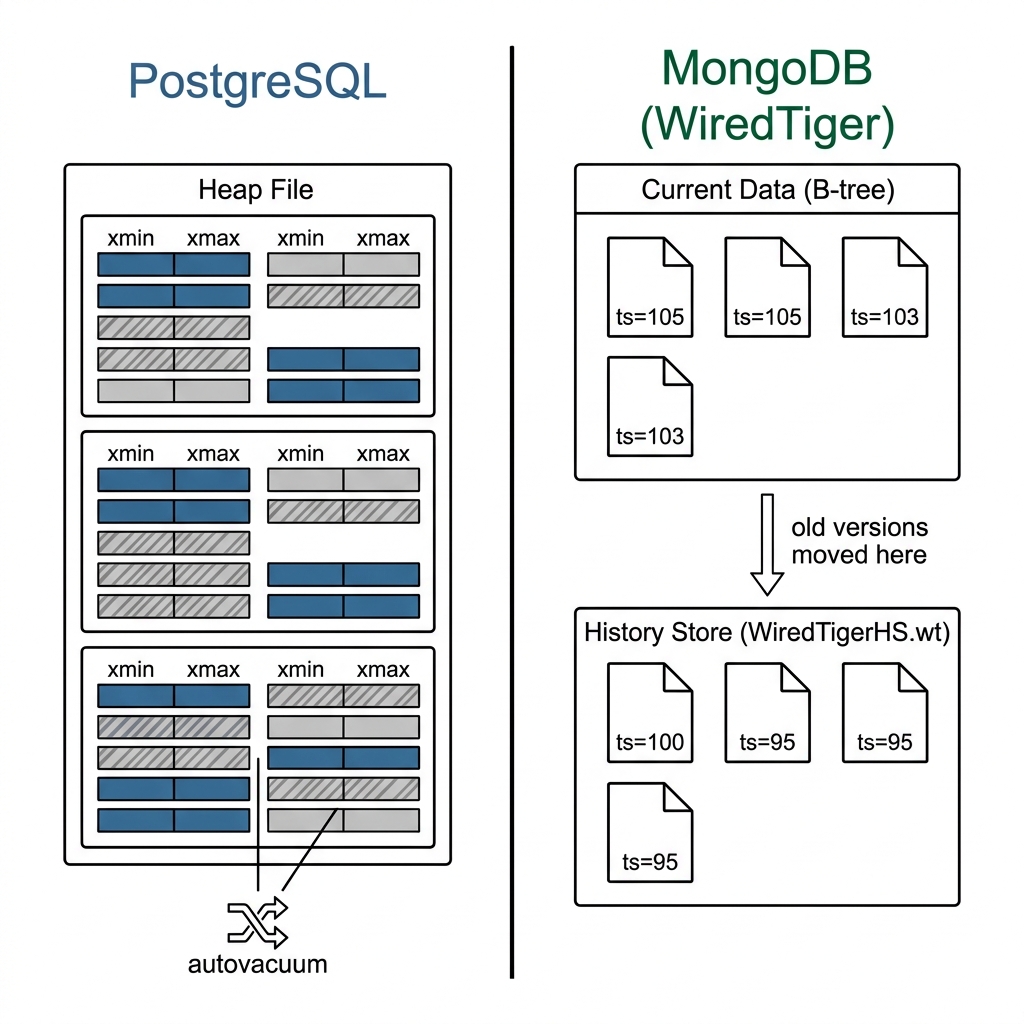
Garbage Collection - History Store
WiredTiger keeps old document versions in a structure called the history store (called the lookaside table before MongoDB 4.4 / WiredTiger 10.0). When no active transaction needs an old version anymore, WiredTiger discards it.
Unlike PostgreSQL’s autovacuum - which has to scan heap files on disk to find and reclaim dead tuples - WiredTiger’s cleanup is tighter because old versions are managed in a purpose-built structure rather than scattered across the main storage file.
The failure mode is still the same. A long-running transaction holds its read timestamp open. WiredTiger cannot discard versions at or after that timestamp. The history store grows. On a heavily written collection under a long-running snapshot, this can become significant.
MongoDB exposes this via the serverStatus wiredTiger command:
db.serverStatus().wiredTiger.cacheWatch these fields:
"pages requested from the cache""tracked dirty bytes in the cache""bytes currently in the cache"
A history store that’s growing faster than it’s being cleaned up will show up as cache pressure before it shows up as latency.
So What?
Schema design affects concurrency. Documents that mix high-read and high-write fields create unnecessary contention. WiredTiger locks at the document level, not the field level. Splitting a hot counter into its own document reduces the blast radius of write conflicts.
Snapshot read concern has a cost. Taking a snapshot across a transaction pins WiredTiger’s read timestamp for the duration of the transaction. Long-running snapshot transactions on busy collections accumulate history store pressure. Keep multi-document transactions short.
Write concern and read concern are two sides of the same question. Write concern controls when a write is considered durable. Read concern controls which writes are visible to a reader. Mismatching them - writing with { w: 1 } but reading with majority - means readers won’t see recent writes until they’re replicated, which can look like stale reads to the application.
The oplog is the replication source of truth. Change streams, MongoDB’s real-time change notification mechanism, are built on top of the oplog. Understanding that they reflect oplog ordering (not WiredTiger commit ordering) explains some of the latency and ordering guarantees (and limitations) change streams provide.
Compared to PostgreSQL
| Feature | PostgreSQL | MongoDB (WiredTiger) |
|---|---|---|
| Version storage | Dead tuples in heap file | History store (on-disk, purpose-built) |
| Cleanup mechanism | autovacuum | Automatic history store eviction |
| Conflict detection | At lock acquisition (row-level locks) | Eagerly, at point of conflict |
| Write conflict retry | Database waits (lock) | Application retries WriteConflict |
| Long-running txn risk | Table bloat, blocked vacuum | History store growth, cache pressure |
The gap that matters most in practice is the cleanup story. PostgreSQL dead tuples live in the heap file until autovacuum reclaims them. On a busy table with infrequent vacuuming, this means real storage bloat and slower sequential scans. WiredTiger’s history store is purpose-built and discards old versions more aggressively, but has the same fundamental constraint - a long-running transaction blocks cleanup.
Comments